Wikipedia has an article that rigorously defines this concept using scaring symbols such as limsup, liminf, bigcap, and bigcup. However, I found a post on MO that explains the same idea intuitively. The keypoint is we can categorize every point ever appearing in the infinite sequence of sets $S_1,S_2,...$ into three partitions:
I) Present in the all but finitely many sets
II) Present only in finitely many sets
III) Present in and absent from the sets infinitely often
If partition III is nonempty then the limit of the sequence clearly doesn't exist. If the limit does exist, then it should contain exactly the points in partition I. The limit of a monotone set sequence always exist because every point in this sequence falls in the first two partitions. Hence for any sequence of sets $S_1,S_2,...$ the following sequences converge: $A_n\equiv \bigcup_{i=1}^n S_i$, $B_n\equiv \bigcup_{i=n}^\infty S_i$, $C_n\equiv \bigcap_{i=1}^n S_i$, $A_n\equiv \bigcap_{i=n}^\infty S_i.$
Showing posts with label Mathematics. Show all posts
Showing posts with label Mathematics. Show all posts
Wednesday, June 22, 2016
Tuesday, October 21, 2014
A note on the strong law of large numbers
I.i.d. r.v.s with zero mean
Consider a sequence of i.i.d. random variables $X_0, X_1, ....$ When the variance is finite, the sequence $S_0, S_1, ...$ of partial sums is expected to have a faster rate of convergence than the rate guaranteed by the Strong Law of Large Numbers (SLLN). In fact, we have the following theorem:Theorem 2.5.1. If $Var(X_n)<\infty$ and $E[X_n]=0$, then $\lim_{n\rightarrow\infty} (S_n/n^p)=0$ a.s. for all $p>\frac{1}{2}$.
This theorem can be proven using criteria of convergent series and the Borel-Cantelli lemma.
Indep. r.v.s with zero mean and finite sum of variance
It is possible to use a denominator with a slower growing rate than $n_p$. However, we will need a stronger assumption for the variances to ensure convergence without a divergent denominator.Theorem 2.5.3. If $\sum_{n\ge1} Var(X_n)<\infty$ and $E[X_n]=0$, then $S_n$ converges a.s.
For sequences with $E[X_n]\neq0$, we can consider $Y_n=X_n-E[X_n]$ instead of $X_n$. Note that $Var(Y_n)=Var(X_n)$ and $E[Y_n]=0$. It then follows from the theorem that $\sum Y_n=\sum (X_n-E[X_n])$ converges a.s.
The ultimate characterisation of independent r.v.s with convergent partial sums is given by Kolmogorov.
Theorem 2.5.4. (Kolmogorov's Three-Series Theorem) Given independent $\{X_n\}$ and $a>0$, define $Y_n=X_n\cdot 1\{|X_n|\le A\}$. Then $S_n$ converges a.s. iff the followings all hold:
(i) $\sum \Pr\{|X_n|>A\}<\infty$, (ii) $\sum E[Y_n]<\infty$, and (iii) $\sum Var(Y_n)<\infty$.
Observe that $\sum_{n\ge1}Y_n<\infty$ a.s by the 2nd condition. Also, putting the 3rd condition and Theorem 2.5.3 together leads to the fact that $\sum_{n\ge1}(Y_n-E[Y_n])$ converges a.s. Finally, $\Pr\{X_n=Y_n$ for $n$ large$\}=1$ by the 1st condition and the Borel-Cantelli lemma. Hence, we see that $\sum_{n\ge1}X_n$ converges a.s. We need the Lindeberg-Feller theorem to prove the other direction.
Convergence of sequence is linked to the SLLN by the following theorem.
Theorem 2.5.5. (Kronecker's Lemma) If $a_n\nearrow\infty$ and $\sum_{n\ge1}b_n/a_n$ converges, then $\sum_{n\ge1}^N b_n/a_N \rightarrow 0$ as $N\rightarrow\infty$.
I.i.d. r.v.s with finite mean
The SLLN follows by Kolmogorov's Three-Series Theorem and Kronecker's Lemma.Theorem 2.5.6. (SLLN) If $E[X_n]=\mu$, then $S_n/n=\mu$ a.s.
Faster rate of convergence
We can prove a faster rate of convergence under stronger assumptions.Theorem 2.5.7. Suppose that $\{X_n\}$ are i.i.d., $E[X_n]=0$ and $\sigma^2=E[X_n^2]$, then for all $\epsilon>0$, $$\lim\frac{S_n}{\sqrt n (\log n)^{1/2+\epsilon}}=0\quad a.s.$$The most exact estimate is obtained from Kolmogorov's test (Theorem 8.11.3): $$\lim\frac{S_n}{\sqrt n (\log \log n)^{1/2}}=\sigma\sqrt 2\quad a.s.$$
Theorem 2.5.8. Suppose that $\{X_n\}$ are i.i.d., $E[X_n]=0$ and $E[X^p]<\infty$ for $1<p<2$. Then $\lim S_n/n^{1/p}=0$ a.s.
Examples
Example 2.5.3. Suppose $\{X_n\}$ is indep. and $\Pr\{X_n=\pm n^{-p}\}=1/2$. Then $p>1/2$ iff $S_n$ converges a.s. (Hint: use Theorem 2.5.4 and let $A=1$)References
Rick Durrett. Probability: Theory and Examples. Edition. 4.1.Friday, October 10, 2014
A note on the Riemann integral of sin(x)/x
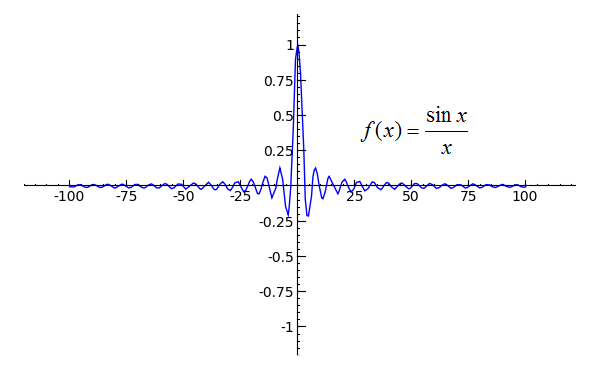
Thursday, September 18, 2014
An algebraic method for a graph decomposition problem
Let $K_{n}$ denote an $n$-clique and $K_{n,m}$ denote a complete bipartite
graph. We are interested in the least number $m$, denoted as $m(n)$,
such that $K_{n}$ can be edge-decomposed into $m$ complete bipartite
graphs. Observe that $m(1)=0$, $m(2)=1$, $m(3)=2$,
$m(4)=3$, etc. It is not difficult to deduce $m(n)\le n-1$ after some
case studies, since we can obtain a decomposition of $K_{n+1}$ by
adding $K_{1,n}$ to a decomposition of $K_{n}$, which implies $m(n+1)\le m(n)+1$.
The nontrivial part lies in the reverse direction: how can we prove a strict
lowerbound for $m(n)$? If we want to establish the lowerbound by
analyzing the graphs directly, we have to show for all $K_n$ that there is no better decomposition than the one we offer, and this is far from an easy job.
R.$~$Graham proposed a very clever method to establish $m(n)\ge n-1$ based on elementary knowledge from linear algebra. He used $n$ variables $x_{1},...,x_{n}$ to represent the $n$ vertices $v_{1},...,v_{n}$ of $K_{n}$. An edge $\overline{v_{i}v_{j}}$ is selected iff $x_{i},x_{j}$ are both nonzero. The key observation is: if $(A_{1},B_{1}),...,(A_{m},B_{m})$ is a decomposition of $K_{n}$ into complete bipartite graphs, then the equation \[ \sum_{1\le i < j\le n}x_{i}x_{j}=\sum_{k=1}^{m}\sum_{x\in A_{k}}\sum_{y\in B_{k}}xy=\sum_{k=1}^{m}\left(\sum_{x\in A_{k}}x\right)\left(\sum_{y\in B_{k}}y\right) \] must holds for any assignment of $x_{1},...,x_{m}$. (An equation like this is called a double counting in the buzzwords of Combinatorics.)
With the observation in mind, he considered the following homogeneous system of linear equations: \[ \begin{cases} \sum_{i=1}^{n}x_{i}=0,\\ \sum_{x\in A_{k}}x=0, & k=1,...,m \end{cases} \] Now suppose that $m < n-1$. The system then has $n$ unknowns and $m+1 < n$ equations. This implies that the system has an infinitely number of solutions. In particular, there exists a nontrivial assignment for $x_{1},...,x_{n}$ such that \[ 2\cdot\sum_{1\le i < j\le n}x_{i}x_{j}=\left(\sum_{i=1}^{n}x_{i}\right)^{2}- \sum_{i=1}^{n}x_{i}^{2}=-\sum_{i=1}^{n}x_{i}^{2}=0, \] which is impossible since the last equality enforces $x_{1}=...=x_{n}=0$. It follows that $m(n)\ge n-1$ by contradiction. Hence, we can conclude $m(n)=n-1$.
R.$~$Graham proposed a very clever method to establish $m(n)\ge n-1$ based on elementary knowledge from linear algebra. He used $n$ variables $x_{1},...,x_{n}$ to represent the $n$ vertices $v_{1},...,v_{n}$ of $K_{n}$. An edge $\overline{v_{i}v_{j}}$ is selected iff $x_{i},x_{j}$ are both nonzero. The key observation is: if $(A_{1},B_{1}),...,(A_{m},B_{m})$ is a decomposition of $K_{n}$ into complete bipartite graphs, then the equation \[ \sum_{1\le i < j\le n}x_{i}x_{j}=\sum_{k=1}^{m}\sum_{x\in A_{k}}\sum_{y\in B_{k}}xy=\sum_{k=1}^{m}\left(\sum_{x\in A_{k}}x\right)\left(\sum_{y\in B_{k}}y\right) \] must holds for any assignment of $x_{1},...,x_{m}$. (An equation like this is called a double counting in the buzzwords of Combinatorics.)
With the observation in mind, he considered the following homogeneous system of linear equations: \[ \begin{cases} \sum_{i=1}^{n}x_{i}=0,\\ \sum_{x\in A_{k}}x=0, & k=1,...,m \end{cases} \] Now suppose that $m < n-1$. The system then has $n$ unknowns and $m+1 < n$ equations. This implies that the system has an infinitely number of solutions. In particular, there exists a nontrivial assignment for $x_{1},...,x_{n}$ such that \[ 2\cdot\sum_{1\le i < j\le n}x_{i}x_{j}=\left(\sum_{i=1}^{n}x_{i}\right)^{2}- \sum_{i=1}^{n}x_{i}^{2}=-\sum_{i=1}^{n}x_{i}^{2}=0, \] which is impossible since the last equality enforces $x_{1}=...=x_{n}=0$. It follows that $m(n)\ge n-1$ by contradiction. Hence, we can conclude $m(n)=n-1$.
Monday, July 21, 2014
Multivariate Lagrange Interpolation
Let $P_{m}^{n}$ denote the vector space formed by real-coefficient,
$m$-variable polynomials of degree at most $n$. The dimension of
$P_{m}^{n}$ is $d=\tbinom{m+n}{n}$, since each polynomial in $P_{m}^{n}$
consists of at most $\tbinom{m+n}{n}$ monomials. Therefore,
if $P\subset P_{m}^{n}$ is an independent set of cardinality
$d$, then every polynomial in $P_{m}^{n}$ can be uniquely represented
by a linear combination of polynomials in $P$. Consider a function
$f\in P_{m}^{n}$ which can only be accessed as a black-box. That
is, we can request it for value $f(\v s)$ at any point $\v s\in\R^{m}$,
but the explicit representation of $f$ is hidden from us. In such case,
Lagrange interpolation offers us a possibility to determine
the function by sampling and evaluating points from its domain.
The basic idea behind Lagrange's method is to choose $d$ points $\vv{\v s}1,\dots,\vv sd\in\R^{m}$ and compute a set of polynomials $P=\{L_{1},\dots,L_{d}\}\subset P_{m}^{n}$, which we shall called a Lagrange basis, such that $L_{i}(\vv sj)=[i=j]$ for $1\le i,j\le d$. Observe that $P$ is an independent set, and thus polynomials in $P$ uniquely determine polynomials in $P_{m}^{n}$.
Given a set of points $\vv s1,\dots,\vv sd\in\R^{m}$, we can use a procedure proposed in [1] to compute a Lagrange basis from the points. First, let $\{q_{1},\dots,q_{d}\}\subset P_{m}^{n}$ denote the set of monomials in $P_{m}^{n}$. Consider polynomial functions $M_{1},\dots,M_{d}\in P_{m}^{n}$ defined as: \[ M_{i}(\vv x{})=det\begin{bmatrix}q_{1}(\vv s1) & \cdots & q_{d}(\vv s1)\\ \vdots & & \vdots\\ q_{1}(\v x) & \cdots & q_{d}(\v x)\\ \vdots & & \vdots\\ q_{1}(\vv sd) & \cdots & q_{d}(\vv sd) \end{bmatrix}\leftarrow\mbox{the $i$th row} \] Observe that $M_{i}(\vv sj)=0$ for $i\neq j$, and $M_{1}(\v s_{1})=\cdots=M_{d}(\v s_{d})=M$ for some $M\in\R$. If $M=0$, then there is no Lagrange basis associated with the points. If $M\neq0$, then $\{M_{i}(\v x)/M:\,i=1,\dots,d\,\}$ is a Lagrange basis. Hence, any polynomial $f\in P_m^n$ can be written in the Lagrange form as $$f(\v x)=\sum_{i=1}^{d}f(\vv si)M_{i}(\v x)/M.$$ Remark. The fact that $M=0$ reflects a geometrical dependency among the $d$ sampling points, in which case it is impossible to determine a unique polynomial from these points. Characterizing the geometry configuration of the points that lead to $M=0$ is an intricate research problem. See e.g., [2] for more details.
2. Olver, Peter J. "On multivariate interpolation." Studies in Applied Mathematics 116.2, 2006.
The basic idea behind Lagrange's method is to choose $d$ points $\vv{\v s}1,\dots,\vv sd\in\R^{m}$ and compute a set of polynomials $P=\{L_{1},\dots,L_{d}\}\subset P_{m}^{n}$, which we shall called a Lagrange basis, such that $L_{i}(\vv sj)=[i=j]$ for $1\le i,j\le d$. Observe that $P$ is an independent set, and thus polynomials in $P$ uniquely determine polynomials in $P_{m}^{n}$.
Given a set of points $\vv s1,\dots,\vv sd\in\R^{m}$, we can use a procedure proposed in [1] to compute a Lagrange basis from the points. First, let $\{q_{1},\dots,q_{d}\}\subset P_{m}^{n}$ denote the set of monomials in $P_{m}^{n}$. Consider polynomial functions $M_{1},\dots,M_{d}\in P_{m}^{n}$ defined as: \[ M_{i}(\vv x{})=det\begin{bmatrix}q_{1}(\vv s1) & \cdots & q_{d}(\vv s1)\\ \vdots & & \vdots\\ q_{1}(\v x) & \cdots & q_{d}(\v x)\\ \vdots & & \vdots\\ q_{1}(\vv sd) & \cdots & q_{d}(\vv sd) \end{bmatrix}\leftarrow\mbox{the $i$th row} \] Observe that $M_{i}(\vv sj)=0$ for $i\neq j$, and $M_{1}(\v s_{1})=\cdots=M_{d}(\v s_{d})=M$ for some $M\in\R$. If $M=0$, then there is no Lagrange basis associated with the points. If $M\neq0$, then $\{M_{i}(\v x)/M:\,i=1,\dots,d\,\}$ is a Lagrange basis. Hence, any polynomial $f\in P_m^n$ can be written in the Lagrange form as $$f(\v x)=\sum_{i=1}^{d}f(\vv si)M_{i}(\v x)/M.$$ Remark. The fact that $M=0$ reflects a geometrical dependency among the $d$ sampling points, in which case it is impossible to determine a unique polynomial from these points. Characterizing the geometry configuration of the points that lead to $M=0$ is an intricate research problem. See e.g., [2] for more details.
References
1. Saniee, K. "A simple expression for multivariate Lagrange interpolation." SIAM Undergraduate Research Online, 2008.2. Olver, Peter J. "On multivariate interpolation." Studies in Applied Mathematics 116.2, 2006.
Friday, February 21, 2014
Paradoxes in the World of Probability
Gambler’s ruin
Consider a symmetric random walk on line $x\ge 0$ starting from some $c>0$. Suppose the walker stops when he reaches $x=0$. Let $X(t)$ denote the location of the walker at time $t$. Then $\Pr(X(t)=0\ \mbox{for some}\ t)=1$, but $E[X(t)]=c$ for all $t$. The latter can be seen by noting that $X(t) = X(t-1) + Y$ where $\Pr(Y=1)=\Pr(Y=-1)=0.5$. (It might be surprising that $E[X(t)]$ is the same as in an unbounded random walk.)Furthermore, if we define the time to stop as $T_k=\inf\{t:X(t)=k\}$, then for any $c>0$ we have $Pr\{T_0<\infty\}=1$ but $E[T_0]=\infty$. This is because that the distribution of $T$ is very heavily tailed. In fact, one can show that $\Pr\{T\ge n\}\approx \frac{a}{\sqrt{n}}$ for some constant $a$. An intuition to see $E[T]=\infty$ is as follows. Since $E[T_0] = c\cdot E[T_{c-1}]$, it suffices to consider $E[T_{c-1}]$. Conditioning on the direction of the first step: \begin{eqnarray*} E[T_{c-1}] & = & E[T_{c-1}\ |\ \mbox{left}] \Pr(\mbox{left}) + E[T_{c-1}\ |\ \mbox{right}] \Pr(\mbox{right})\\ & = & (1 + E[T_{c+1}]) \cdot 2^{-1}\\ & = & (1 + 2\cdot E[T_{c-1}]) \cdot 2^{-1} = 2^{-1} + E[T_{c-1}]. \end{eqnarray*} Hence the only possibility is $E[T_{c-1}] = \infty.$
The St. Petersburg paradox I
Consider a game where a player flips a fair coin and wins $2^n$ dollars if the head turns up at the $n$th flip. The game continues until the head turns up. Then the expect amount of money a player can win from the game is $\sum_{n\ge1} 2^n\cdot 2^{-n} = \infty$. Hence, to make this game fair, a player should pay an infinite amount of money to play this game!The St. Petersburg paradox II
Following the previous example, how much should a player be charged if he is only allowed to play for at most $N$ rounds? Denote the reward of the player as $S_N$. It is tempting to estimate the reward by $E[S_N]=\sum_{n=1}^N 2^n\cdot 2^{-n} = N$. However, it can be shown that $\frac{S_N}{N\lg N}\rightarrow 1$ almost surely. Namely, when $N$ is large, the player is very likely to win about $N\lg N$ dollars from this game. Hence, $N\lg N$ is arguably a more reasonable price than $N$ to charge the player.A winning strategy for a fair game
Consider a game where a player bets $X_n\ge0$ dollars on the $n$th round, $n\ge1$. After $X_n$ is decided, a fair coin is flipped. The player loses the bet if the tail turns up, and wins another $X_n$ dollars otherwise. Here is a strategy that guarantees a player to win 1 dollar almost surely from this game: (i) set $X_1=1$, (ii) set $X_{n+1}=2^n$ if he lost the $n$th round, and (iii) set $X_n=0$ for $n>N$ if he wins the $N$th round. Suppose the head first turns up at the $N$th flip. Then the expected amount of money he can win from the game is $2^N-(1+2^1+\cdots+2^{N-1})=1$ dollar. However, although the average number of rounds for this strategy is $1/0.5=2$, you are expected to pay $1\cdot 2^{-2}+2\cdot 2^{-3}+...=1/4+1/4+...=\infty$ dollars before you can get the dollar.Waiting time for a better offer
Suppose you want to sell you car on the Internet. It turns out that if the offers to buy your house are i.i.d., then you may expect to wait forever to get an offer better than the first offer. To see this, denote the first offer by $X_0$ and the sequence of offers by $\{X_n:n\ge0\}$. Let $N=\inf\{n:X_n>X_0\}$ be the waiting time until the first offer better than $X_0$. Note that $$\Pr\{N>n\}=\Pr\{X_0=\max_{0\le k \le n} X_k\}\ge \frac{1}{n+1}$$ by symmetry. Hence $E[N]=\sum_{n\ge0} \Pr\{N>n\} = \sum_{n\ge1} \frac{1}{n} = \infty$. This fact suggests that you should accept the first offer if you have to make decision immediately after after an offer is made, and cannot change your mind after you made a decision.Power of hints in a fair game
A banker tosses two fair coins and then covers the coins. To play this game, you choose to uncover one of them in blind. You win this game if the coin you choose is head.Case 1. Without further information, you have a 1/2 chance to win regardless of the coin you choose.
Case 2. Suppose the banker uncovers one of the two coins. If you decide to choose the other coin, the chance you win is still 1/2 regardless of the result of the former coin. Hence, uncover a coin doesn't provide any information for the other coin.
Case 3. Suppose the banker peeked the coins before they are covered, and he tells you that one of the coins is head. Then whatever coin you choose, you have 2/3 probability to win.
Case 4. Following case 3, suppose the banker not only tells you that one of the coins is head, but also uncovers that coin. If you choose the other coin, your chance to win declines to 1/3.
Case 5. Suppose the banker peeked the coins before they are covered. He tells you that one of the coins is tail. Then whatever coin you choose, you have 1/3 probability to win.
Case 6. Following case 5, suppose the banker not only tells you that one of the coin is tail, but also uncovers that coin. If you choose the other coin, then your chance to win increases to 2/3.
Mutually independency does not imply true independency
Let a set $\{X_i\}$ of random variables be $k$-independent if $$\Pr(X_i) = \Pr(X_i\ |\ X_{a1},...,X_{ak})$$for any $i\not\in\{a1,...,ak\}$. Namely, one cannot infer the value of $X_i$ given the values of up to $k$ other random variables. Given any $k>2$, it is easy to construct $k+1$ random variables $X_0,...,X_k$ that are mutually independent but not $k$-dependent. Let $U_0,...,U_k$ be iid random variables uniformly distributed over $1,...,N.$ Define $X_i=U_i−U_{i+1~\rm{mod}~k+1} \mod N$. Since $X_0+\cdots+X_k=0$, they are obvious not $k$-independent. It is also easy to show that $X_i$ and $X_j$ are independent for $i\neq j$. In fact, $X_0,...,X_k$ are $m$-independent for any $2\le m <k.$An immediate consequence of this fact is: $\Pr(X) = \Pr(X\ |\ Y)$ and $\Pr(X) = \Pr(X\ |\ Z)$ doesn't imply that $\Pr(X) = \Pr(X\ |\ Y,Z)$.
Friday, January 31, 2014
Tossing coins
Simulate a biased coin with a fair coin
The following algorithm simulates a biased coin with head probability 0<p<1, using a random number generator toss_coin that returns 0 and 1 with equal probability.// Pre-condition: p is a rational number and 0 < p < 1
while (true) {
var p = p * 2,
var p2 = p - floor(p);
var msb = p - p2;
var random_bit = toss_coin(); // 0 or 1
if (random_bit < msb) {
print "head";
break;
}
if (random_bit > msb) {
print "tail";
break;
}
p = p2;
}
// Post-condition: "head" is outputted with probability p
// "tail" is outputted with probability 1-p
To see why it works, consider a random number 0 < r < 1 generated by enumerating its binary representation with a fair coin. Observe that given 0 < p < 1, the probability that 0 < r < p is exactly p. The algorithm then enumerates p and r, digit by digit, and determines the return value according to the following fact: r < p if and only if ri < pi for some i and rj = pj for all j < i, where xk denotes the kth digit in the binary representation of x.
The following code fragment is adapted from the book Abstraction, Refinement and Proof for Probabilistic Systems, A McIver, C Morgan, 2005. Succinct as it is, its behavior is not as straightforward to understand as the above one and we skip the analysis of its correctness.
// Pre-condition: p is a rational number and 0 < p < 1
var x = p;
while (toss_coin() == 1) {
x = 2 * x;
if(x > 1){
x = x - 1;
}
}
// Post-condition: x > 0.5 with probability p
print x > 0.5 ? "head" : "tail";
Simulate a fair coin with a biased coin
while (true) {
var a = toss_biased_coin();
var b = toss_biased_coin();
if(a == b){
print a == 1 ? "head" : "tail";
break;
}
}
The expected running time is $\frac{2}{1-2p(1-p)}$.
Checking whether a coin is fair
First, note that it is impossible to rule out arbitrarily small deviations from fairness such as might be expected to affect only one flip in a lifetime of flipping. Also, it is always possible for a biased coin to happen to turn up exactly 10 heads in 20 flips. As such, any fairness test must only establish a certain degree of confidence in a certain degree of fairness (a certain maximum bias). In more rigorous terminology, this problem can be viewed as a special case of determining the parameters of a Bernoulli process, given only a limited sample of Bernoulli trials.Suppose that there are $h$ heads and $t$ tails in an experiment of $n=h+t$ tosses. The best estimator for the actual head probability $p$ is $$q=\frac{h}{h+t}.$$ One can associate this estimator with a margin of error $\epsilon$ at a particular confidence level, which is given by the Z-value of a standard normal distribution in the following sense: $$P\{|p-q|\le z\sigma\}=P\{|Z|\le z\},$$ where $\sigma$ is the standard deviation of error of the estimate and $Z$ is a standard-normal distributed random variable. For $n$ Bernoulli trials, the standard deviation is $$\sigma=\sqrt{\frac{p(1-p)}{n}}\le\frac{1}{2\sqrt n}.$$ Hence, suppose that $P\{|Z|\le z\}=c$ then we have $$P\{|p-q|\le \frac{z}{2\sqrt n}\}\ge c.$$ For example, by looking up the table we see that $z=2.5759$ for $c=99\%$. Suppose now $h=54$ and $t=46$, then the actual head probability $p$ falls into $0.54\pm 0.12879$ at 99% level of confidence.
Subscribe to:
Posts (Atom)
